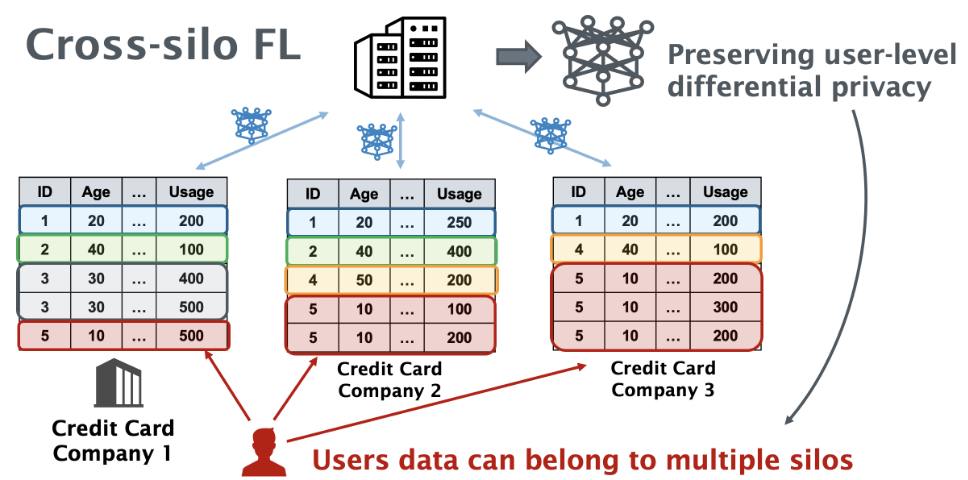
Scenario
保护用户分布在不同的 Silo 中的记录.
Difference
-
重新定义 User-Level
- 区分 Record-Level & User-Level, User-Level Privacy & Group Privacy
Record-Level DP User-Level DP Group DP 1 record as a privacy unit User’s all records as a privacy unit k records as a privacy unit 相邻数据集最多 1 条记录不同 相邻数据集最多 1 个用户不同 相邻数据集最多 k 条记录不同 之前 ULDP 在 FL 上也有研究, 但研究仅将用户数据归属于单个设备. 相当于是 Client-Level DP.
-
现有 Cross-Silo FL 聚焦于 Record-Level DP, 还没有研究过 User-Level DP.
-
现有使用 Paillier 密码的进行加权求和的方法, 没有考虑到拥有 Paillier 私钥的一方可以得到原始数据. 本研究使用 Paillier, 安全聚合和乘法盲化进行了优化.
Baseline Method
转化为 GDP 实现 ULDP.
ULDP-NAIVE
与 DP-FedAVG 类似, 添加 的高斯噪声, 但因为用户会存在于各个 Silo 中, 所以单个用户会对所有 Silo 的模型都有贡献, 因此跨 Silo 的敏感度为 , 因此需要将噪声放大为 ,使来自 个 Silo 的聚合结果满足所需的 DP.
ULDP-GROUP-k
先使用 flag B 限制每个用户在所有 Silo 中的记录在 k 条. 再使用 DP-SGD 将 Record-Level DP 转化为 GDP. flag B 中用 表示用于训练.
ULDP-NAIVE 和 ULDP-GROUP 在服务器处的全局学习率为 .
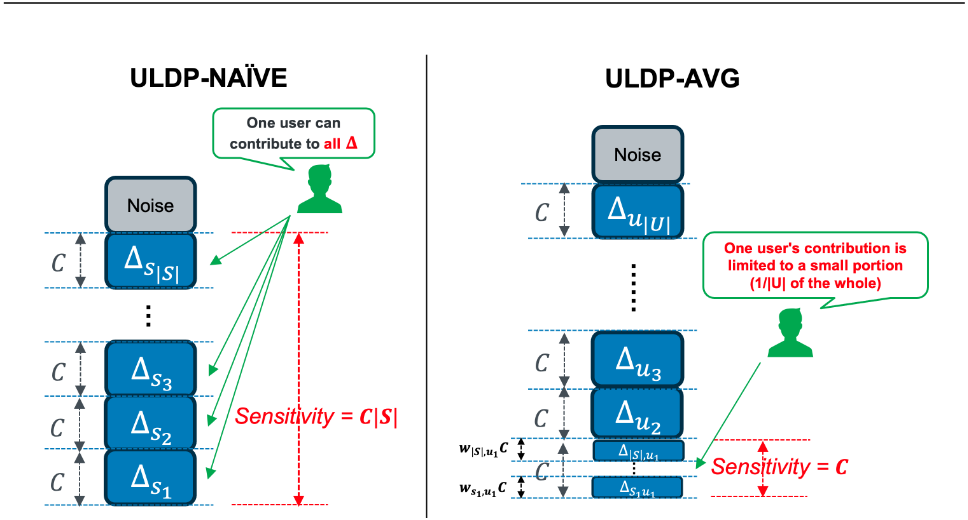
Advance Method
直接实现 ULDP.
ULDP-AVG/SGD
ULDP-AVG 比 ULDP-SGD 多了在本地进行多轮计算随机梯度值.
ULDP-AVG/SGD 在服务器处的全局学习率为 . 默认权重为 . 添加的高斯噪声大小为 . 将用户的贡献对模型的贡献压缩在一起, 在所有 Silo 中添加的噪声和为 .
ULDP-AVG with user-level sub-sampling
若使用 ULDP-AVG with user-level sub-sampling, 则在服务器端对用户按概率为 q 进行泊松采样.
在服务器处的全局学习率为 .
- 采样更多, 消耗的隐私预算越多, 但可以获得更高的准确率.
- 在大量用户的场景下, sub-sampling 的效果更显著, 也更重要.
- Creditcard 1000 users
- MNIST 10000 users
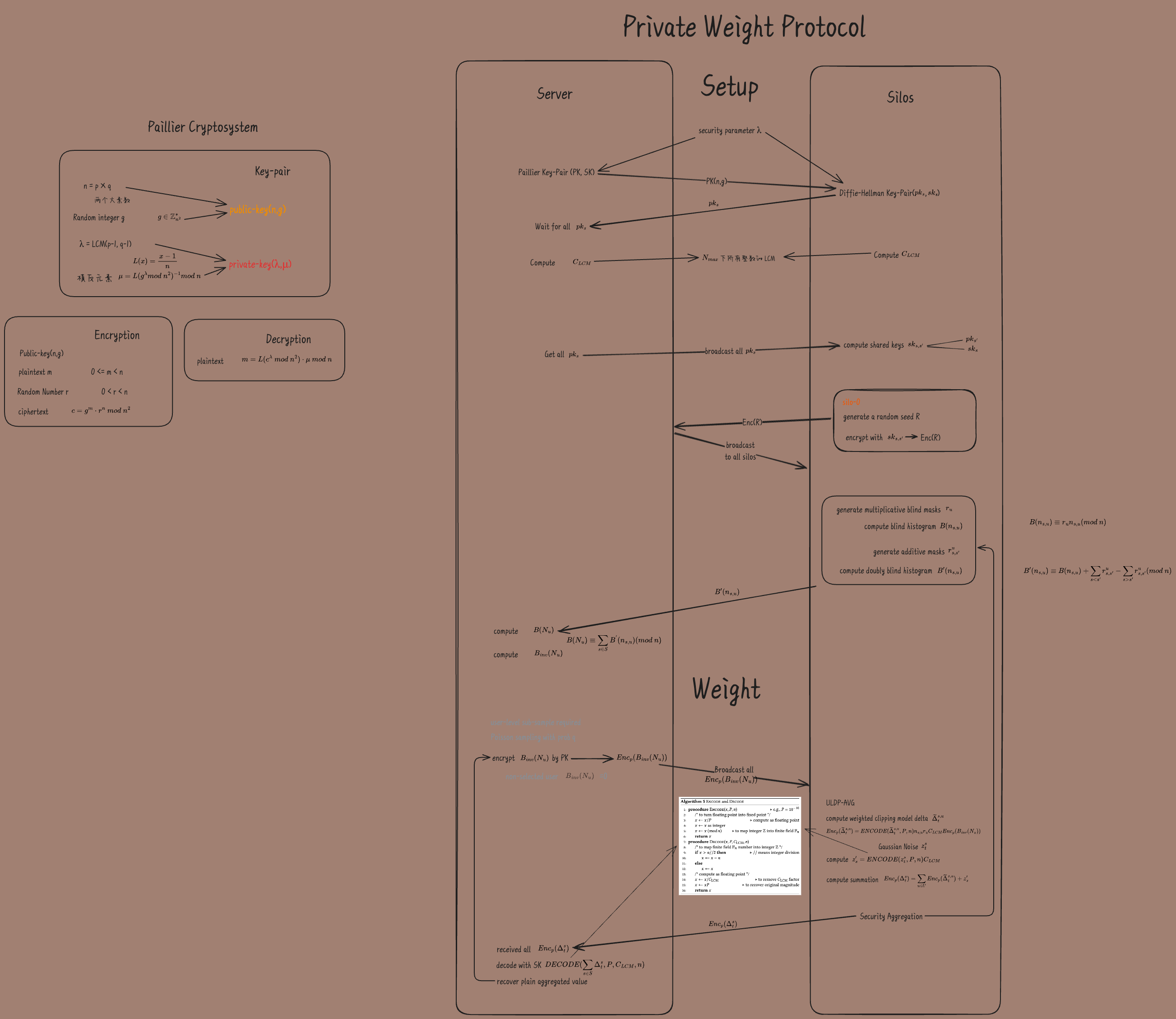
Private Weight Protocol
ULDP-AVG-w 优化权重为 .
协议使用 multiplicative blinding 来隐藏用户的直方图. 这样服务器可计算盲化 histogram 的逆后,来计算权重, 但仍不知用户真实的 histogram. 服务器再使用 Paillier 加密盲化直方图的逆, silo 知道盲化掩码可以对应得到真实值.
Experiment
Datasets
- Creditcard
- MNIST
- HeartDisease
- TcgaBrca
Dataset Allocation
Creditcard & MNIST
- uniform
user-record, silo-record 等概率
- zipf
record-user: record-silos:
HeartDisease & TcgaBrca
- uniform
user-record 等概率, 不会将 record 分配到 silo
- zipf
用户的记录数量首先按照 Zipf 分布生成, 80% records 分配到一个 silo, 20% records 等概率分配到其他 silos.