综述重点
创新的差分隐私联邦学习分类

联邦学习本身是一个复合框架 中央服务器可能需要在聚合模型参数的同时,进行本地训练
讨论 DP、LDP 和 Shuffle Model 在联邦学习中的隐私保证
- 主要是 DP、LDP 和 Shuffle Model
- 关注三者的保证和定义
- 区别于基于是否存在中央可信服务器的分类方法
DP 和 ShuffleModel 中的 Sample Level 和 Client Level 是通过临近数据集进行进一步分类
- 常用属性
- 隐私损失构成机制
- 扰动方法
关注水平/垂直/转移联邦学习
- 水平联邦学习 HFL(主要场景)
- 垂直联邦学习 VFL
- 转移联邦学习 TFL
VFL 和 TFL 还存在较多隐私问题
联邦学习 Fedreated Learning
特点
参与者在本地在本地进行学习,保留敏感原始数据,仅上传模型的参数到服务器
技术
- 同态加密 Homomorphic Encryption
- 加密数可以在不解密的情况下,进行特定操作。
- E(a),E(b),a和b在不解密的情况下,计算E(a·b),E(a+b)
- 多方计算 Multiparty Computation(MPC)
- 每个参与方只知道自己的输入和输出,而不会获得其他参与方的输入数据。最终通过gong xia共享的部分得到结果
两种技术都需要大量计算,且不能保护最终输出避免隐私泄露
分类
水平联邦学习 HFL
- , :本地数据集,:所有数据集集合
- :损失函数
- :轮数
- :客户端序号
- 客户端使用不同样本,共享相同的特征空间
- 不存在一个具体的服务器,所有参与者都是客户端,最终将各参数聚合在集中服务器中
垂直联邦学习 VFL
- 每个客户端使用不同的样本和特征空间,最终综合所有客户端的特征空间,可以获得比 HFL 效果更好的预测器
- 拥有标签的 Kth 作为服务器,其他的作为客户端
转移联邦学习 TFL
-
客户端之间特征/样本空间重叠区域有限或没有,让多方参与服务器数据的归纳且不用相互暴露数据
-
客户端拥有带标签的 source domain datasets
-
服务器用于不带标签的 target domain datasets
-
- :损失函数
- :轮数
- :客户端序号
差分隐私 Differential Privacy
- 差分隐私可以很好地降低联邦学习的隐私风险
- 通过在本地训练阶段/上传模型参数时,添加适当的 DP 噪声
其他综述聚焦应用数据
- 图数据 Graph Data
- 医疗数据 Medical Data
- 自然语言处理 Natural Language Processing
- 工业物联网 Industrial internet of things
分类
DP
通过在统计查询的输出中增加适量噪音来抵御差分攻击 数据查询阶段添加噪声
DP
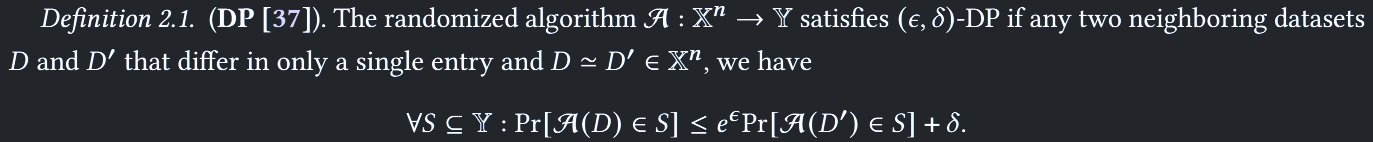
- 可省略
- 当 时,
- 越小,隐私水平越高
Label DP
保护信息中只有标签是敏感的情况 常用于垂直联邦学习

Bayesian DP
关注攻击者在观察隐私模型后的后验分布与先验分布的变化 BDP 与 DP 的定义很相似,但 BDP 会用到数据集中的所有样本

Local DP
相比于 DP,LDP 更严格,且不需要可信的数据收集器 数据收集阶段添加噪声 但数据扰动函数从收集器处转移到每个用户 用户使用隐私保护算法对原始数据进行扰乱,并上传到收集器
LDP
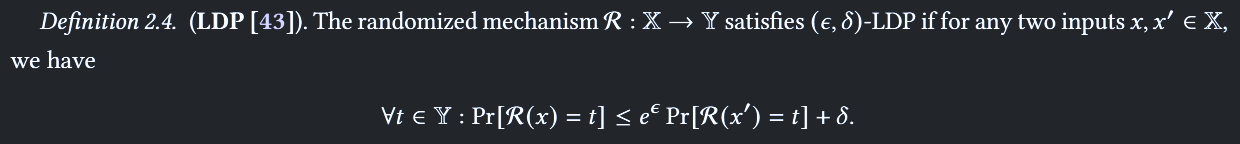
- 和 DP 中一样可省略
- 当 时,
- 控制两个记录输出的相似性,避免通过输出来推断输入数据
LDP 隐藏了过多信息,导致一些应用不可用
CLDP
CLDP 基于度量扩展 LDP 提高了可用性 通过判断任意一对敏感数据间的距离来评定隐私保证水平

- 若 d 增大,则 需要减小,以平衡补偿
Shuffle Model
权衡 隐私保护 - 交流效率 - 模型表现
客户端在面对 Shuffler 时,满足 LDP 的隐私保证 客户端在面对服务器时,满足 DP 的隐私保证
-
- :分析器
- :Shuffler
- :随机生成器
- 满足 ,则 也就满足
Shuffle 还可以增加用户隐私性,可以在本地进行随机化处理,还可以在其他客户端进行,并且可以有更少的损失。
如果想在本地随机化达到相似的隐私水平需要更少的噪声
三者关系
DP-LDP
- DP 依赖于邻近数据集,而 LDP 并无邻近数据集这个概念
- 当样本为 1 或样本都来自一个数据集时,DP 和 LDP 会很相似,可以从 DP 推导出 LDP,LDP 可以满足 DP 的要求
但 LDP 不能推出 DP,DP 不一定能满足 LDP 的要求
Shuffle Model-DP-LDP
Shuffle Model 包含 DP 和 LDP 的技术和概念 Shuffle Model 接收到客户端发送的数据,然后让模型参数匿名化并生成一个数据集(邻接数据集)
基础属性&损失构成机制
基础属性
- 后处理

- 后处理不会减弱隐私水平
- 后处理后还会保持为
- 平行构成特性
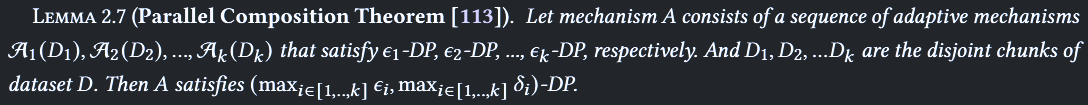
- DP 分别在数据集分成不相交的区块中运行
- 每条数据只会出现在一个区块中
[[#水平联邦学习 HFL|HFL]] 每个客户端使用不同的样本,也相当于不相交,所以也有这个特性 [[#转移联邦学习 TFL|TFL]] 也是数据集基本不相交,聚合后符合这个特性
- 顺序构成特性

- 通过汇总多个隐私算法的预算来满足总的隐私预算
- 可以利用这个特性来计算预算
损失构成机制
实现对保障隐私更紧密的分析 相同的预算,添加更少的噪声达到相同隐私水平
通过添加噪声来隐藏原始信息,添加越多噪声,隐私保护性越强,但会相对降低模型的性能 所以这个机制可以在添加较少的噪声的情况下,获得一个更好的隐私保护性
可以利用这些构成机制来汇集隐私损失转换成 的形式来进行比较
MA 和 RDP 都可以最作为衡量两个随机分布可区分性的指标
-
Moments Accountant


-
Rényi DP



-
Gaussian DP

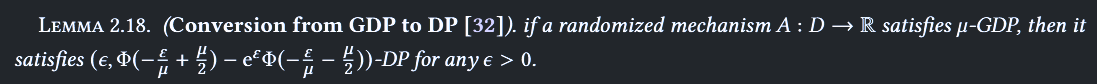
- Trade-off 函数
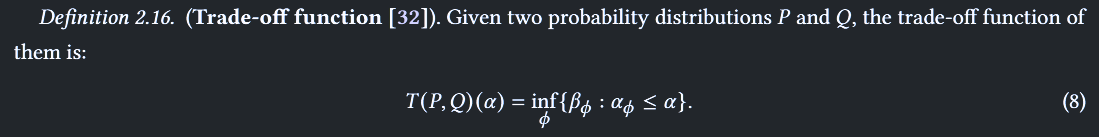
- 使用假设来量化两个数据集间的差异
- H0 假设:不存在差异
- H1 假设:存在差异
- 拒绝规则 :否认假设的概率
- I 型假设:否认 H0 假设
- II 型假设:否认 H1 假设
- Trade-off 函数
类比于机器学习 I 型假设相当于误报,将负例误判为正例 II 型假设相当于漏报,将正例误判为负例
- Zero-Concentrated DP

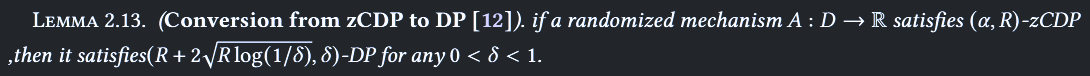
差分隐私联邦学习 DPFL

扰乱机制
添加噪声进行扰乱,扰乱机制即噪声的算法
DP-FL
- 高斯机制(最常用)
- 离散高斯机制(常用)
- Skellam 机制
- 二项式机制
- 泊松二项式机制
LDP-FL
- 拉普拉斯机制
- 值扰动
- 无界噪声(噪声取值无上下界)
- 来自 DP 数据发布场景,用于平均值估计
- 随机回复机制 RR
- 值扰动
- 有界噪声(噪声取值有上下界)
- 来自 LDP 数据收集场景,用于离散值计数估计
- 两个步骤
- 扰动
- 校准
- 指数机制
- 值选择
- 用于离散元素选择
- 基于 RR - Duchi 机制
- 连续数据估计平均值
- 基于 Duchi - Harmony 机制
- 连续数据估计平均值
- 结合拉普拉斯和 Duchi - 分段机制
- 连续数据估计平均值
- 广义随机回复机制 GRR
- 离散值计数估计
- 对 RR 的扩展
- 基于 RR - RAPPOR
- 使用布隆过滤器来实现对大型域中离散频率的估计
DP-HFL
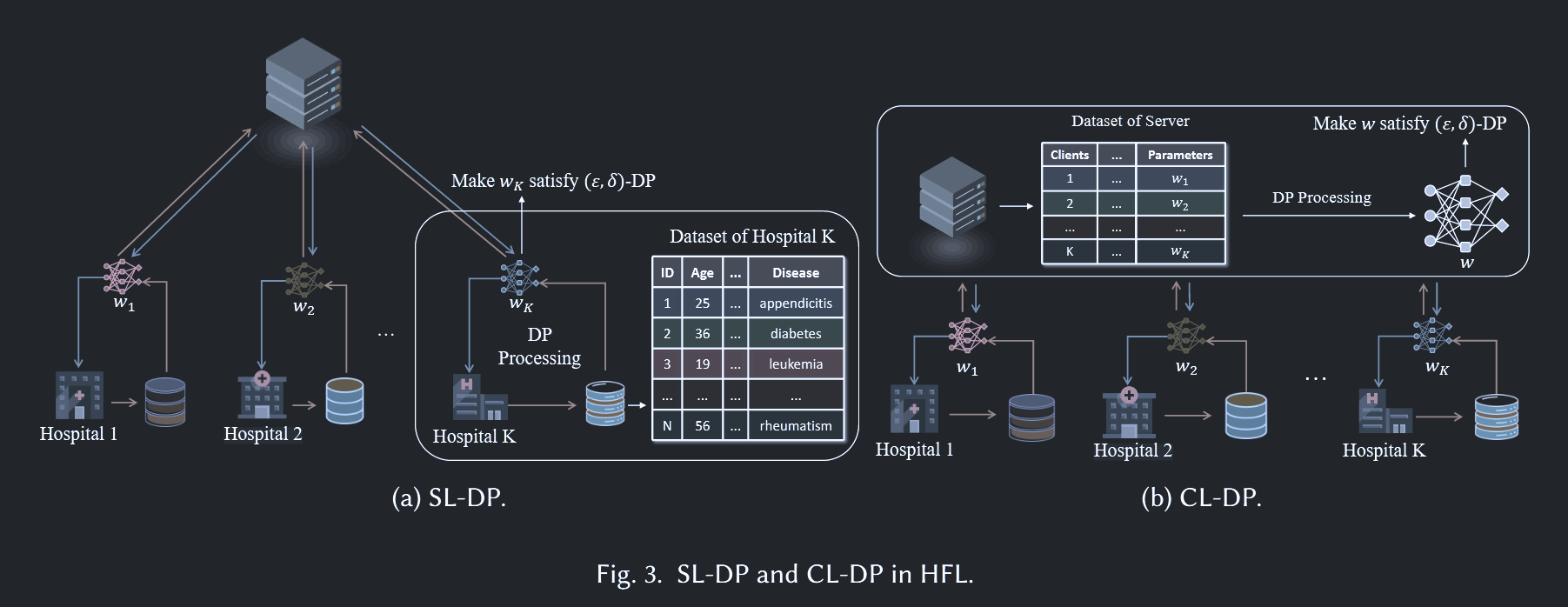
Sample-Level DP
服务器半诚实(诚实&好奇)
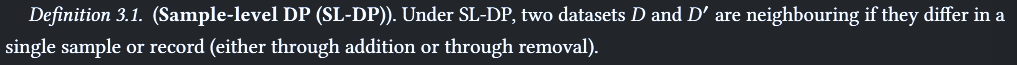 各个客户端都拥有自己本地的数据库
目标是隐藏样本的存在,不能让攻击者验证某个样本
各个客户端都拥有自己本地的数据库
目标是隐藏样本的存在,不能让攻击者验证某个样本
- DPSGD ^48cfe1
- DP Stochastic Gradient Descent 随机梯度下降
- DPSGD 将所有样本的取值裁剪在一个合理的范围中,并添加随机噪声保证不暴露原始数据,模糊了单一样本对模型的影响
还需要注意隐私预算的分配,隐私预算决定了迭代轮数和噪声规模等因素,会直接影响训练模型的性能
- 数据异质化
- 各个客户端收集的数据不尽相同
- 数据的特征,年龄,职业,体重,…
- 数据的数量,1000 条,100 条,…
- 数据的标签,鸟,猫,狗,…
- 各个客户端收集的数据不尽相同
特征空间和标签分布的不同在于,一个标签拥有多个特征,特征空间异质性是针对于一个主体的特征的不同,标签分布异质性是对于多个标签主体的不同
- ADMM
- Alternating Direction Method of Multipliers 交替方向乘法
- ADMM 引入拉格朗日乘数来分解问题,然后逐一解决直到收敛
Client-Level DP
服务器完全诚实(诚实&不好奇)
 目标是隐藏客户端的存在,不能让攻击者验证某个客户端的特征
目标是隐藏客户端的存在,不能让攻击者验证某个客户端的特征
相比于 SLDP,CLDP 是对客户端训练后的特征进行操作,也是先进行裁剪再添加噪声随机化,然后上传到可信中心服务器进行聚合
CL-DP with Secure Aggregation
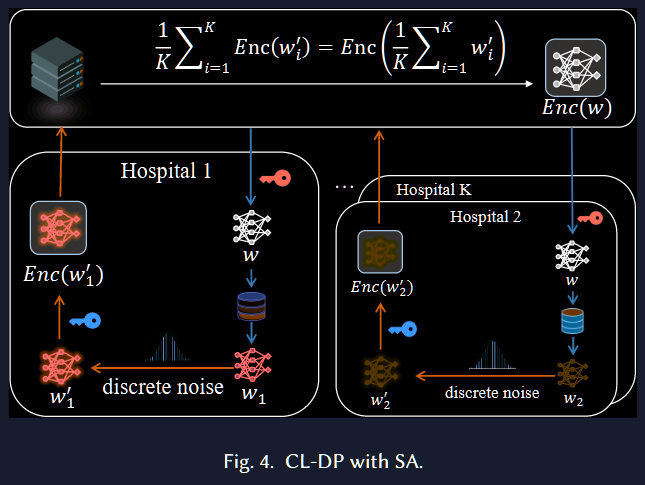
通过上传加密数据来避免数据泄露,即使服务器不完全可信,也无法还原原始客户端数据
LDP-HFL
LDP 存在高维数据处理的问题,主要是因为客户端在进行扰动时的性能问题,导致无法合理分配预算
- 优化隐私预算分配的方法
- 自适应-Duchi机制
- FedSel框架
- 指数机制的多维选择(EM-MDS)
- 减少噪声影响的方法:
- 分段机制和混合机制
- 三输出机制
- 最优分区机制
- 数据扰动前的预处理:
- 阶梯随机响应(SRR-FL)
- 直接扰动原始数据的方法:
- RAPPOR方法
- 卷积和池化后的扰动
Shuffle Mode-HFL
Shuffle Mode-HFL 是隐藏了客户端和客户端上传特征的对应关系
客户端 → Shuffler(打乱关系)→服务器
所以即使服务器不完全可信,也可以对客户端有一定的保护性
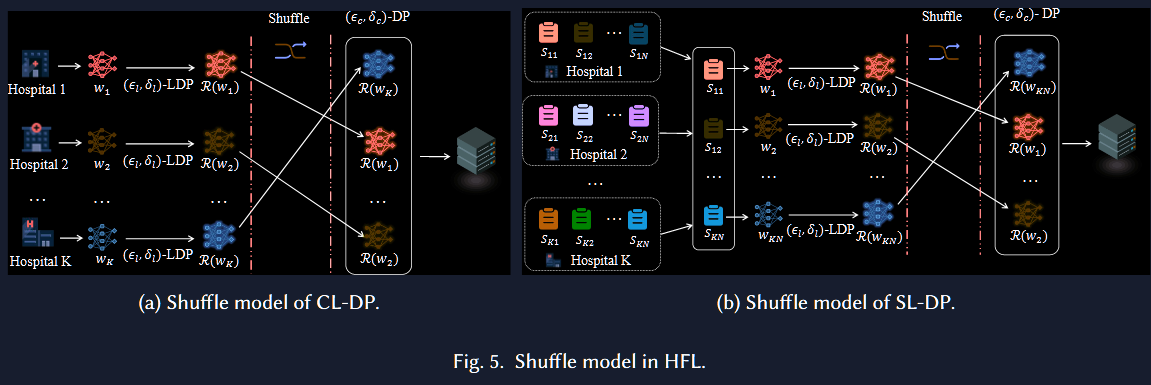
数据首先在客户端处进行更新扰动,符合 LDP 的隐私标准
- CLDP 是对客户端整体的数据进行扰动
- SLDP 是对样本数据进行扰动
小结
- 仅 CL-DP 需要完全可信的服务器
- CL 保护客户端,SL 保护样本
- CL 和 LDP 参与的客户端越多越好,SL 参与的客户端包含的样本越多越好
- 对比
- SL-DP vs LDP
- SL-DP 会对每个样本都添加噪声,而 LDP 仅在上传时添加一次噪声
- LDP 维度越多(数据量越大),需要添加的噪声越多,相对会降低越多的准确度;SL-DP 受到的影响较少
- LDP vs CL-DP with SA
- LDP 会添加大量的噪声来保护隐私
- CL-DP with SA 中各个客户端添加少量噪声,聚合后也能满足保护隐私
- SL-DP vs LDP
DP-VFL
VFL 适用于不同客户端拥有同一样本的不同特征时,以扩展特征的维度 但客户端发送预测结果到服务器是,特征有可能会被推测出来
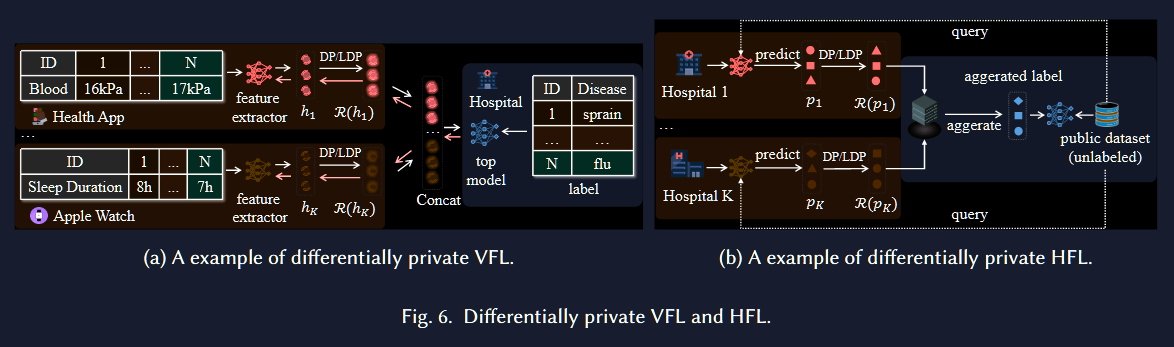
DP-TFL
TFL 适用于客户端所拥有的样本和特征很少的情况
将客户端已有的样本和特征作为教师模型 未标记的公共数据集作为学生模型 聚合每个客户端拥有的少量的样本生成一个大的模型,对学生模型进行训练
数据类型应用
图
GNN 核心操作是消息传递。不仅依赖本节点,也取决于邻居节点
添加噪声
敏感度决定 DP 添加噪点的等级 敏感度需要通过当前节点对邻居节点的依赖程度来确定
比如,某一个邻居节点微小的变化后,当前节点会有很大的改变,则说明敏感度高,需要添加越大规模的噪声来隐藏这种大的变化
梯度扰动
采样限制节点的入度、测量依赖级别的上限,使用 [[#^48cfe1|DP-SGD]]
但随着GNN层数的增加,依赖程度和敏感性也会增加,需要添加更多的噪声,可能会影响模型的性能
二分矩阵
显示反馈
- 明确表达出喜好,1-5 分评分
- 使用矩阵分解模型作为构建块
- 随机梯度下降、交替最小二乘法
隐式反馈
- 隐含可能喜好偏向,点赞、转发
- 使用联邦协同过滤,必须添加更多的噪声,才可以满足无界的隐私要求
时间序列
在时间维度上,攻击者可以观察多个不同的隐私保护输出
将时间序列数据划分为多个粒度(日、周、月),对每个粒度的数据添加差分隐私噪声
实际应用
自然语言处理
健康医疗
处理通过互联网医疗设备(IoMT)和分布式医疗数据集时的患者数据保密性问题
- 人工噪声
- 随机梯度下降和同态加密
- 电子健康记录(EHR)建模
物联网
解决边缘计算、能量收集和资源受限设备上的隐私保护问题