Cause
最近在准备托福写作,在考满分的网站上看往年的题目。在网站上写作保存起来很别捏,最近又正在习惯在 Obsidian 上进行输出。既然要在 Obsidian 上写作,那就不得不同时打开浏览器来看题目了(我属于是看完题目就忘了那种)。
那为什么不直接把题目复制进 Obsidian 呢?
既然要复制,我可不想每次都一段一段的复制,而且 Task 1 还有听力部分,还是得打开浏览器。所以琢磨了一下,简单的写了一个小脚本生成需要的 Markdown 文件。
脚本的逻辑很简单,一点点积累自己的技能。 代码写的没那么优雅,大佬轻喷🙏
Frame
#Python #BeautifulSoup #jinja2 #request
Process
Markdown 模板
首先准备了一个用于输出的 Markdown 模板,规定好需要获得的信息和输出的位置。
## Task Description
**index:** {{index}}
**category:** {{category}}
{{des}}
<audio controls>
<source src="{{audio_url}}" type="audio/mp3">
</audio>
[Click to check Original]({{origin_url}})
Markdown 支持内嵌 HTML,所以需要播放音频就嵌入了播放器。将音频的 URL 填入即可播放。
jinja2使用{{ }}来规定对应变量输出的位置。
// 设置环境
env = Environment(loader=FileSystemLoader('.'))
// 遍历所有话题
for task in tasks:
// 获得模板文件
template = env.get_template('Integrated Writing.md')
// 将 task 中的数据按模板中位置进行输出
rendered_markdown = template.render(task)
// 设置文件输出位置
with open('Z:/Note/aBER_Cloud/0x05_Task/1_TOEFL/1_Writing/2_Write/' + task['index'] + '.md', 'w', encoding='utf-8') as file:
file.write(rendered_markdown)
处理&输出
 主要用字典数组来存每个话题的信息。
主要用字典数组来存每个话题的信息。
// 字典数组
tasks = [
{
'index': Task_Title, // 标题
'category': Task_Category, // 分类
'origin_url': Task_Page_URL, // 页面链接
'des': Task_Description, // 题目描述
'audio_url': Task_Audio_URL // 音频文件链接
}
]
处理都是通过 requests GET 到 HTML 页面后,再使用 BeautifulSoup 进行处理。
在话题集合页面可以遍历获得列表中所有话题的标题,分类和页面链接。
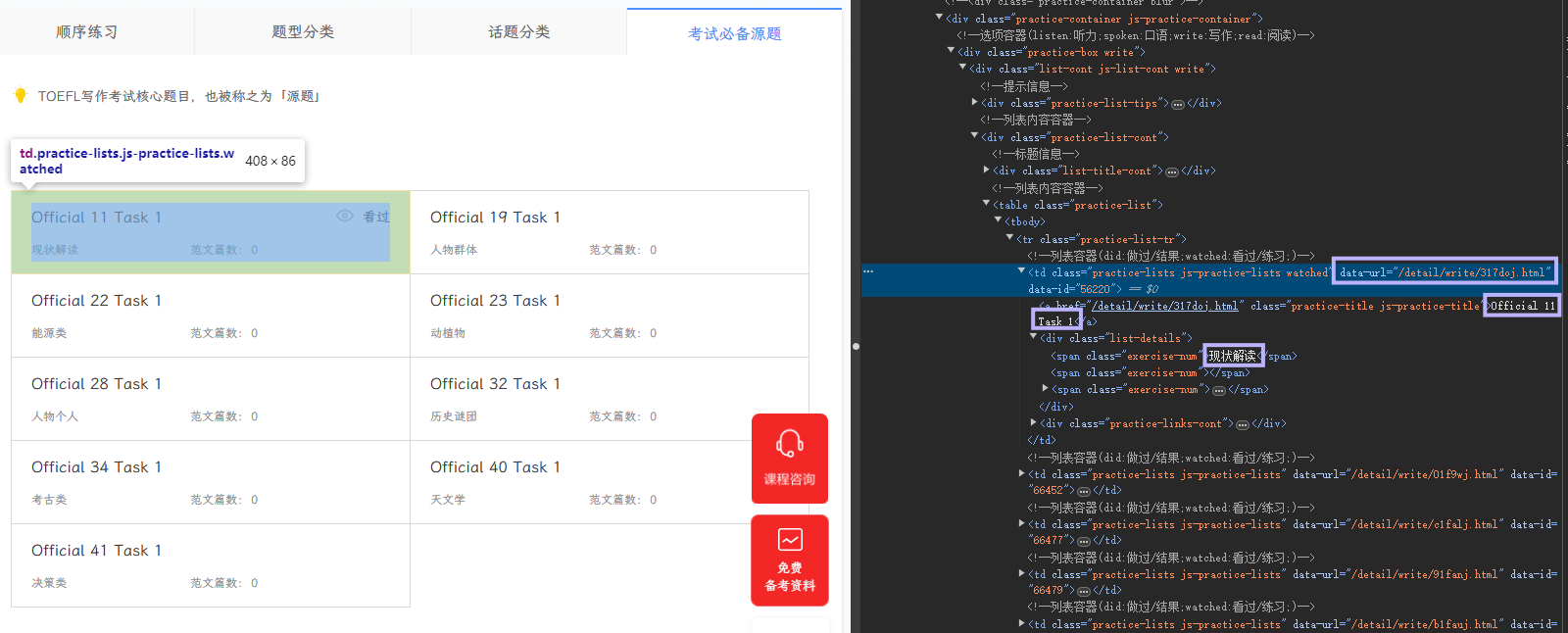
之后对路径进行拼接,获得完整的 URL。
进入话题子页面后,通过 CSS 选择器来查找元素。找到的相关元素后,获得对应的属性即可。
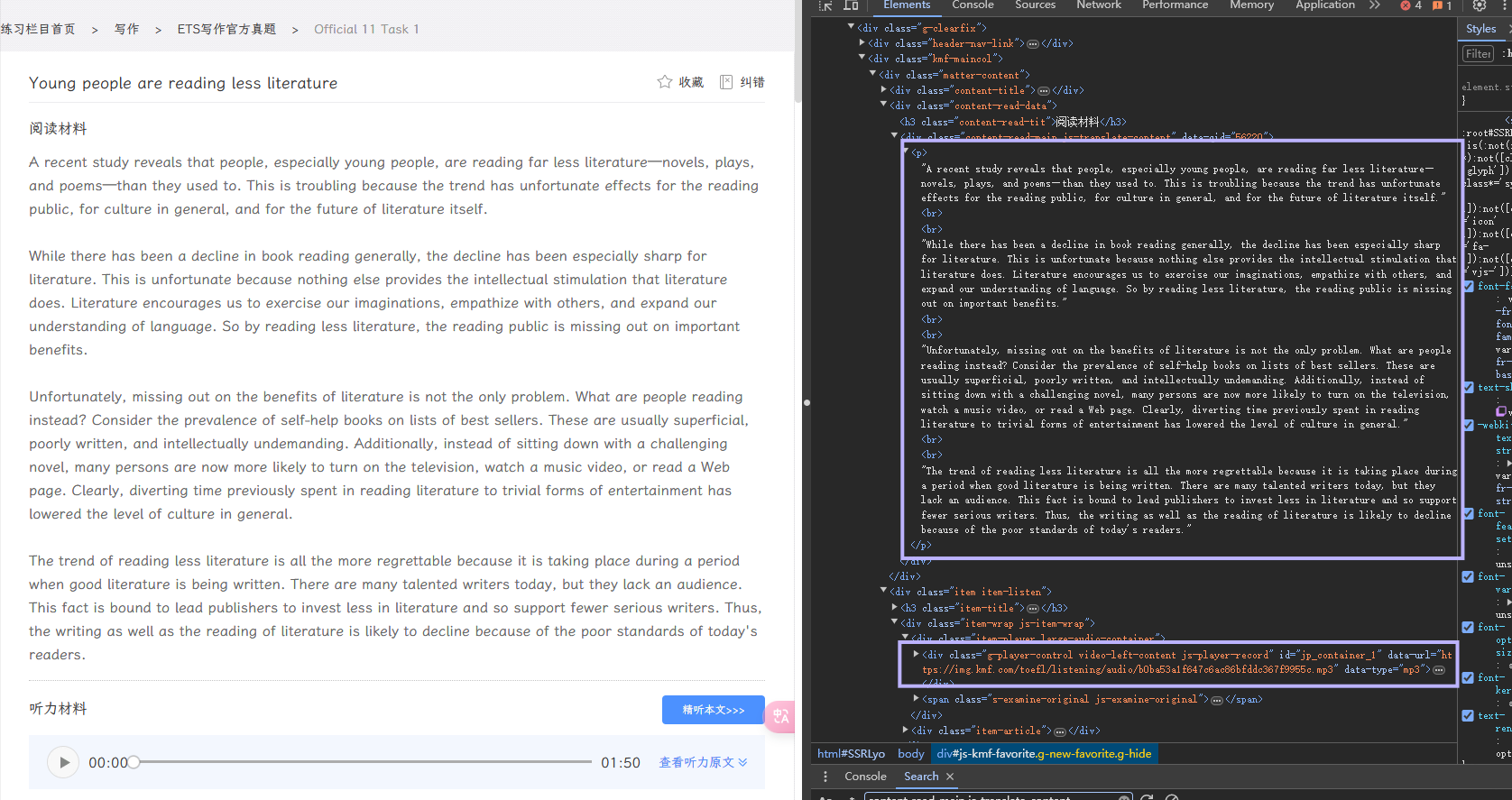
话题描述通过
element.get_text()获得文本。 音频 URL 通过element.get('data-url')获得data-url属性值(即音频 URL)。
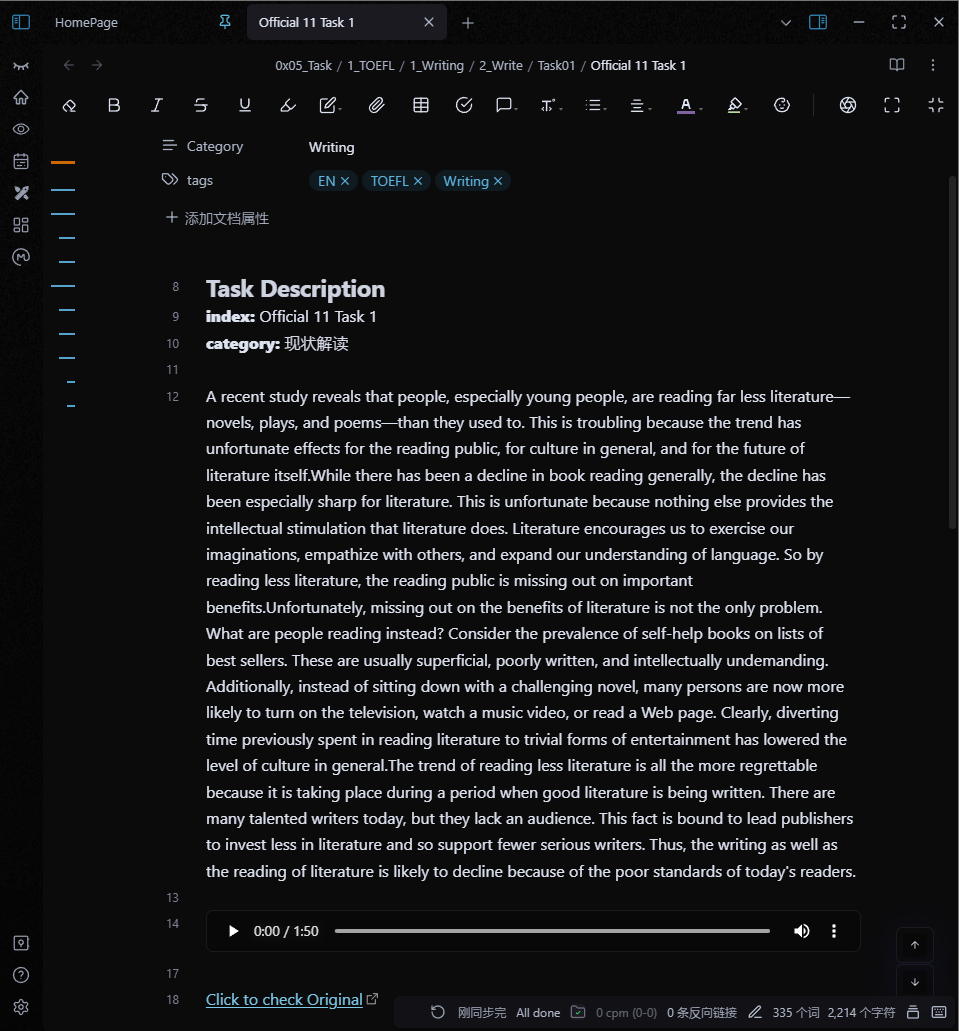
获得所有需要的信息之后,依次输出即可。
输出效果
Code
import requests
from bs4 import BeautifulSoup
from jinja2 import Environment, FileSystemLoader
url = 'https://toefl.kmf.com/write/ets/necessary'
response = requests.get(url)
tasks = []
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
elements_with_data_url = soup.find_all(attrs={'data-url': True})
for element in elements_with_data_url:
entry = {
'index': element.find(class_='practice-title js-practice-title').get_text(),
'category': element.find(class_='exercise-num').get_text(),
'origin_url': 'https://toefl.kmf.com' + element['data-url']
}
tasks.append(entry)
for task in tasks:
try:
response = requests.get(task['origin_url'])
response.raise_for_status()
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
element = soup.find(id='jp_container_1')
if element != None:
task['audio_url'] = element.get('data-url')
else:
task['audio_url'] = "NO_AUDIO"
if task['audio_url'] != "NO_AUDIO":
element = soup.find(class_='content-read-main js-translate-content').find('p')
else:
element = soup.find(class_='content-subject js-translate-content').find('p')
if element != None:
task['des'] = element.get_text()
else:
task['des'] = "NO_DES"
except requests.RequestException as e:
print(f"获取 HTML 失败:{e}")
env = Environment(loader=FileSystemLoader('.'))
for task in tasks:
template = env.get_template('Integrated Writing.md')
rendered_markdown = template.render(task)
with open('Z:/Note/aBER_Cloud/0x05_Task/1_TOEFL/1_Writing/2_Write/' + task['index'] + '.md', 'w', encoding='utf-8') as file:
file.write(rendered_markdown)