第一章 概论
- 定义
- 内容的获取、识别和管控/分析
- 内涵
- 法律合法
- 政治健康
- 道德规范
- 安全威胁
- 国家安全
- 公共安全
- 文化安全
- 三分类模型
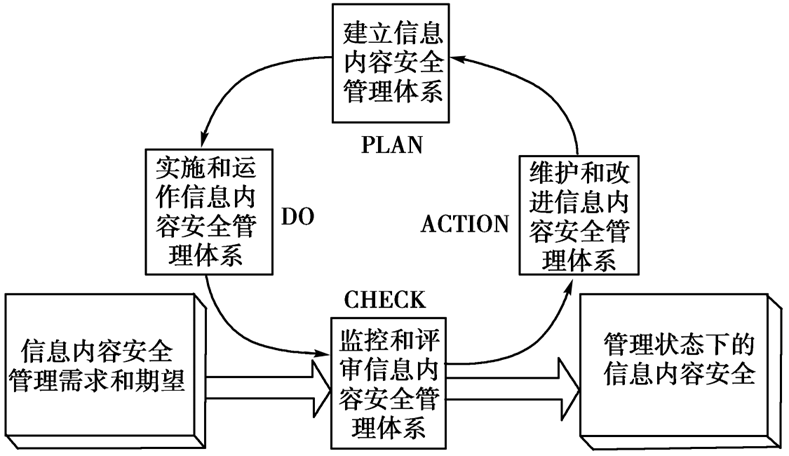
- 戴明环管理框架
- PDCA
第二章 内容获取技术
PageRank 算法
- 信息检索 - 搜索引擎
- PageRank 值越高,网页越重要。
- 基本定义
- 转移矩阵 (结点间的跳转概率矩阵)
- 初始分布向量 (等概率 )
- 一般定义
- 在基本定义上增加平滑项(避免 0 概率)
-
- 为阻尼因子,, 通常取 0.85
- 接近 1,随机游走主要依照 进行
- 接近 0, 随机游走等概率随机访问各结点
- 为阻尼因子,, 通常取 0.85
- 迭代计算
- 与 充分接近则停止
- 计算过程
- 转移矩阵
- 有向图
- 转移矩阵
- dM
- 阻尼因子 = 0.8

- 有向图
- 初始分布向量 (等概率 )
- 最后进行迭代计算
- 迭代公式


- 转移矩阵

协同过滤推荐
- 信息推荐算法
- 通过找到与当前用户相似的其他用户,来加权计算最适合当前用户的商品
-
- 表示求和中仅计算用户已评分的商品
- 用户 与用户 相似度
- 表示用户 对商品 的评分
- 表示用户 已评分商品的平均分
- 为当前用户 与所有用户的相似度绝对值的和的倒数,即
- 计算过程
- 计算用户已评分商品的平均分
- 计算目标用户与其他用户的相似度
- 若没有相同的评分商品则
第四章 文本信息特征处理
特征提取
- 特征项
- 特性
- 能确实标识文本内容
- 能将目标文本与其他进行区分
- 个数不能太多
- 特征项分离比较易实现
- 特征抽取
- 在不损伤文本核心内容的情况下,减少要处理的单词数,降低向量空间维度,简化计算,提升速度和效率
- 特性
- 词级别的语义特征
- 词频
- 中频词更具代表性
- 高频词区分较差
- 词性
- 动词和名词作为特征词
- 虚词(感叹、介词等)要剔除
- 词频
- 计算因素
- 文档/词语长度
- 长词汇含义更明确,更能反映主题
- 词语直径
- 首次出现与末次出现的距离(粗糙的度量特征)
- 首次出现位置
- 关键词一般较早出现
- 越早出现,权重越大
- 词语直径与首次出现位置选一个即可
- 词语分布偏差
- 词语在文章中的统计分布
- 分布均匀的通常为重要词汇
- 文档/词语长度
- 汉语分词
- 特点
- 没有复数变化
- 没有词边界
- 方法
- 正向/反向/双向最大匹配法
- 问题
- 歧义消除
- 新词识别
- 特点
特征子集选择
停用词过滤
- 去除对于分类没有贡献的特征项
- 手工/统计生成
文档频率阈值法 DF
- 齐夫定律
- 单词按频率 由高到低排列
- 单词频率与序号近似反比
TF-IDF
- 文档频率阈值法的补充改进
-
- :包含特征项的样本在全部样本中的占比
- :特征项 在所有训练样本中出现的次数 (出现频率)
- :包含特征项 至少一次的训练样本数
- 相比 DF,增加了包含特征项的样本在整体数据中的分布情况
- 越多样本包含特征项,说明该特征项越重要,即 越大
信噪比
- 信号强度与背景噪声的差值
- 信息熵 (整个系统的平均信息量)
- 噪声
- :特征项 出现在样本 的可能
- 信噪比
-
- 当且仅当特征项 在全部样本中均出现 1 次时取得最小值,
- 说明全是噪声,没有贡献分类能力
- 当特征项 集中出现在 1 个样本中时取得最大值,
- 当且仅当特征项 在全部样本中均出现 1 次时取得最小值,
-
信息增益
- C 的信息熵
- C 关于 T 的条件信息熵
- 信息增益
- 信息熵与条件信息熵的差
-
-
- 样本包含特征项 且类别为
-
- 信息增益越小,说明对于分类的贡献越少,即去除
卡方统计( 统计)
- 观察值与理论值间的偏离
- 特征对某类的 统计值越高,与该类的相关性越大,携带类别信息越多
-
- 观测值
- 理论值
-

第五章 音频数据处理
- 响度级
- 单位
- 方
- 1 方 = 1 kHz 的纯音 1 dB 的声压级
- 人耳听阈对于 0 方
- 方
- 人耳感知的声音响度是频率和声压级的函数
- 主观等响度曲线
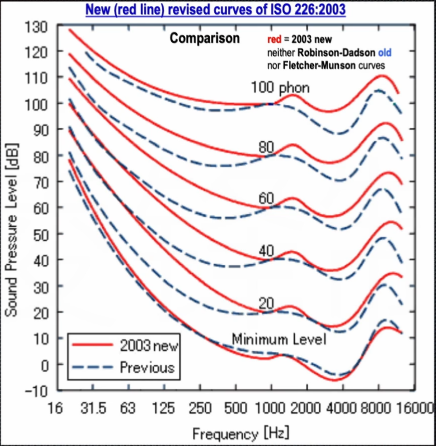
- 每条红线上的点响度相同
- 单位
- 掩蔽效应
- 声音
- 掩蔽音
- 较强的声音
- 纯音调
- 宽带噪音
- 窄带噪音
- 被掩蔽音
- 较弱的声音
- 掩蔽音
- 分类
- 同时掩蔽/频域掩蔽
- 异时掩蔽
- 前掩蔽
- 后掩蔽
- 声音
- 采样率
- 采样率越低,高频信息越少
- 44.1 kHZ CD 最低标准
- 比特深度
- 比特深度越大,动态范围越大,噪音越少
- 16 bit 音乐发行格式
- 语音分帧
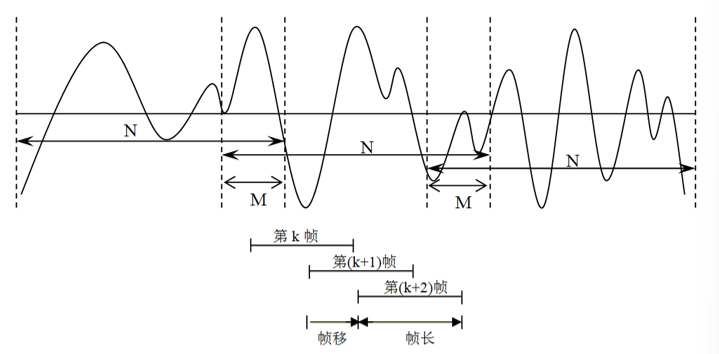
- 使用一定长度的窗序列来截取
- 每秒约取 33-100 帧
- 为保证帧与帧之间平滑过渡,采用交叠分段
- 帧移
- 前后两帧交叠部分
- 帧移与帧长比值取 0-0.5
- 帧移
- 短时过零率
- 语音信号波形穿过横轴的次数
- 连续信号,时域波形穿过时间轴
- 离散信号,取样值改变符号
- 语音信号波形穿过横轴的次数
第六章 图像信息特征抽取
图像表示
- 矩阵表示
- 灰度图像
- 的矩阵存灰度值
- 0(全黑)
- 255(全白)
- 彩色图像
- RGB 通道分为三个矩阵
- 矩阵叠加生成图像
- 灰度图像
颜色直方图特征
- 反映特定图像中的颜色级与出现该种颜色的概率之间关系的图形
- 灰度直方图函数
- :第 个灰度级
- 值越高灰度过渡越多,细节更细致
- 值越低灰度过渡越少,细节更模糊,难以分辨
- :图像中 灰度级的像素点总数
- 分母用来进行归一化处理
- :第 个灰度级
- 颜色直方图函数
- :第(r, g, b)个颜色柄
- : 的像素点总数
- 分母用来进行归一化处理
- 计算流程
- 颜色量化
- 将颜色空间划分成若干个颜色区间,每个区间代表一个颜色柄
- 均匀量化
- 对每个颜色分量的划分是均匀的
- 统计颜色柄中像素点总数
- 计算颜色直方图
- 颜色量化
- 特征特点
- 优点
- 提取方法简单,计算复杂度小
- 图像操作(位移、旋转、镜像等)不会影响该特征
- 局限
- 颜色空间的选取
- 颜色空间
- RGB?
- HSV?
- CIE-Lab?
- RGB 不符合人类对颜色相似的主观判断
- 颜色空间
- 量化方法制定
- 如何去点个量化的阶数
- 颜色空间的选取
- 优点
颜色聚合矢量特征
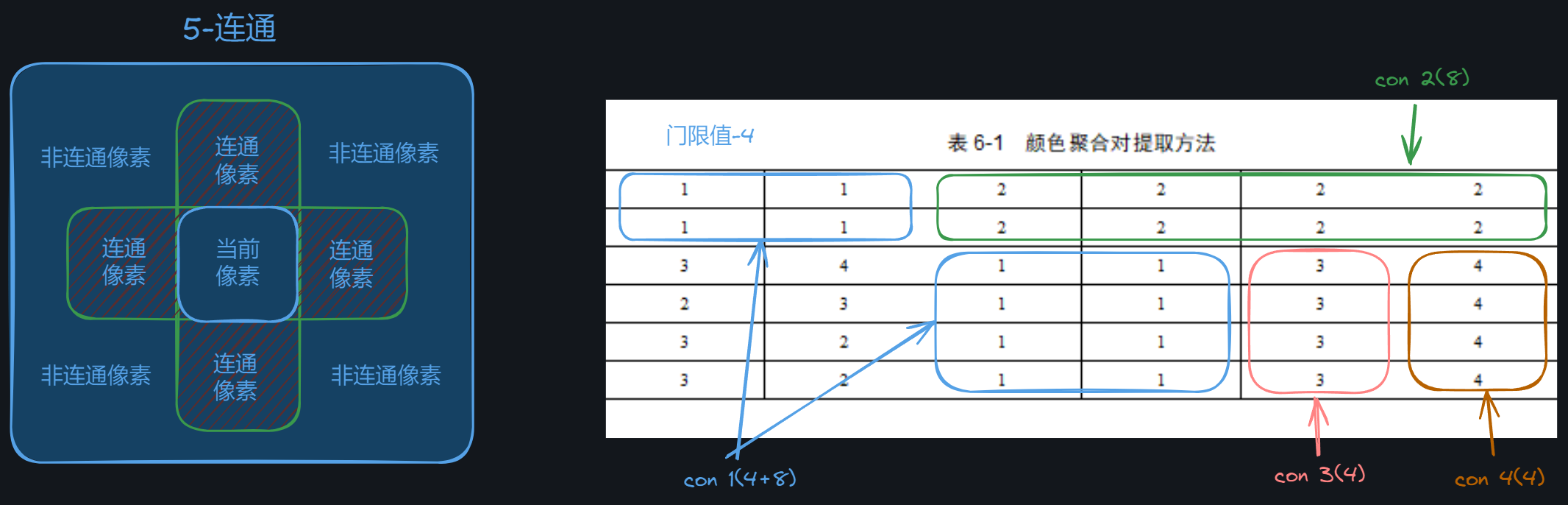
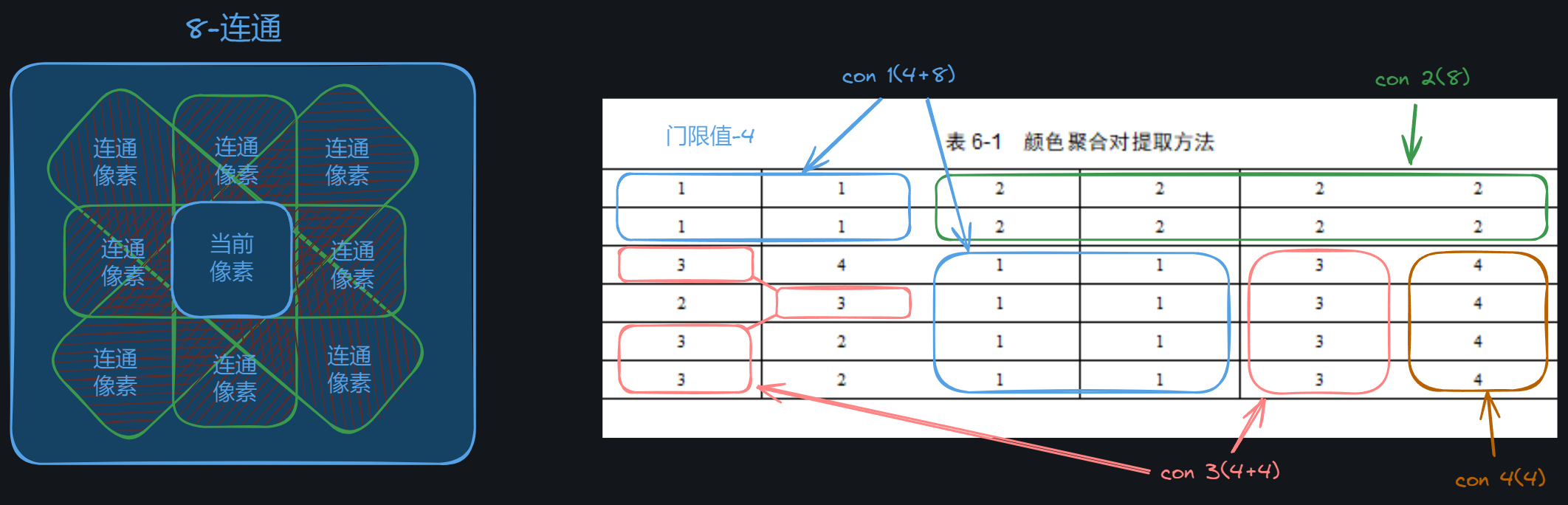
- 引入一定空间信息进一步区分颜色分布类似而空间分布不同的图像
- 计算流程
- 将颜色空间划分成若干个柄
- 颜色柄
- 连贯点
- 颜色相同
- 空间连续
- 离散点
- 第 个颜色柄的颜色聚合对
- 连贯点
- 图像的颜色聚合矢量特征
- :颜色柄总数
- 连贯点与离散点的计算
- 门限 threshold
- 区分是否连续
- 5-连通
- 8-连通
- 门限 threshold
- 局限性
- 颜色空间选取和空间量化方法的制定
- 离散/连贯的门限值设定
- 连续性判断导致计算复杂度变高
颜色矩
- 引入低阶矩描述整个图像的颜色变化
- 常用颜色矩
- 一阶矩-颜色均值
-
- :像素点 的第 个颜色通道的颜色值
- 一般取 ,代表 RGB 三个通道
- :像素点 的第 个颜色通道的颜色值
-
- 二阶矩-颜色标准差
- 三阶矩-颜色偏度
- 一阶矩-颜色均值
- 特点
- 常规 RGB 图像仅需 维,相比其他颜色特征,维数最低
- 仅包含颜色信息,缺乏对细节的描述
第七章 信息处理模型和算法
文本匹配
单模式匹配
- 过程
- 匹配
- 后移
- 算法
- Brute-Force 算法(暴力)
- 最坏时间复杂度
- 将正文分为 个长度为 的子串
- 相当于每次后移一位进行匹配
- 检查每个子串是否与模式串 P 匹配
- 对模式串扫描常常需要回溯,存在许多重复操作,影响效率
- KMP 算法
- 三个人的名字
- Knuth
- Morris
- Pratt
- 通过已匹配的部分来决定后移的位数
- 匹配表
- 模式串对自己进行处理生成的匹配表
- “部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度
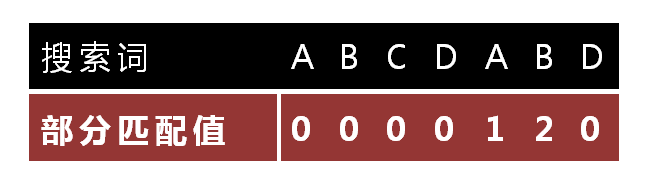
- 模式串对自己进行处理生成的匹配表
- 移动位数 = 已匹配的字符数 - 对应的部分匹配值
- 匹配表
- 时间复杂度
- 预处理阶段
- 平均查找复杂度
- 最坏情况下
- :匹配字符串长度
- :完整字符串长度,
- 三个人的名字
- QS 算法
- Brute-Force 算法(暴力)
多模式匹配 DFSA 算法
机器学习分类
线性分类器
- 通过一个线性判别函数的输出来确定数据类别
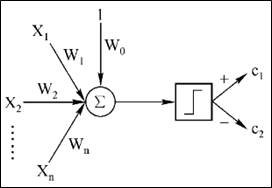
-
- 输出为正,判别为一类
- 输出为负,判别为另一类
- 输出 0,不能做出判断
- 特点
- 线性分类器结构相对简单,学习优化过程计算复杂度低
- 泛化能力较强
- 存在分布不可线性分割的情况
最临近分类法 KNN
- 通过测试样本和训练样本间的距离来进行分类
-
- :类别总数
- :第 类训练样本集
- :测试样本
- 计算与测试样本的距离,选择最接近的 个样本点组成
- 测试样本即分类为 中个数最多的类别
-
- 特点
- 不需要复杂学习优化过程,但需要计算距离,存在一定计算量
- 在一定程度上,可以处理分布较为复杂多样的问题
- 与线性分类器相比,分界面并不是一个超平面,可以是更为复杂的曲线
线性可分支持向量机
- 通过间隔最大化学习得到分离超平面
- 分离超平面
- 分类决策函数
- :用来判断正负
- 点到分离超平面的远近可以表示分类预测的确信程度
- 函数间隔
- 超平面定义
- 所有样本点的函数间隔最小值
- 超平面定义
- 几何间隔
- 表示 向量模长
- 超平面定义
- 所有样本点的几何间隔最小值
- 函数间隔与几何间隔
- 间隔最大化
- 间隔越大,分类确信度越高
- 计算转化
- 计算最大几何间隔
- 几何间隔转为函数间隔
- 转化为最小值问题(最优化问题), 方便计算
- 计算最大几何间隔
- 函数间隔
- 求解分离超平面
- 求最优化问题的最优解 和
- 得到分离超平面 和分类决策函数
- 支持向量
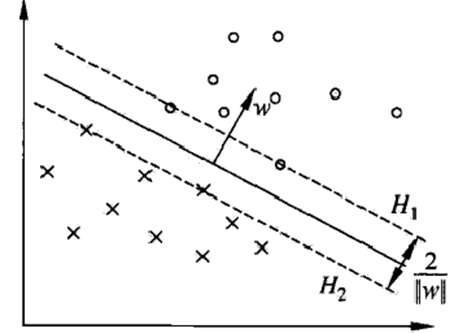
- 分布在间隔边界处的样本点,使约束条件等号成立的点
- 正例的支持向量在
- 负例的支持向量在
- 和 为间隔边界
- 对偶算法
- 用于求解最优化算法
- 引入核函数,推广到非线性分类问题
- 拉格朗日函数
-
- 根据拉格朗日对偶性,求解
- 先求
- 分别对 和 求偏导并令其等于 0
- 得到
- 再算 的对 极大值问题 (对偶问题)
- 等价对偶最优化问题
- 注意限制条件,计算时用于消元
- 计算解得
- 先求
-
- 计算分离超平面和分类决策函数
-
- 代入计算时, 可任取一个训练数据
- 分离超平面
- 分类决策函数
- 计算流程
- 求解最优化问题 ,得到
- 代入计算 和
- 得到分离超平面和分类决策函数
朴素贝叶斯 SVM
- 计算训练集中的各特征分类的概率,再通过比较条件概率来确定
- 计算过程
- 极大似然估计
- 先计算各特征分类的概率
- 通过统计数据集得到
- 数据集中共 15 条数据,Y=1 有 7 条,Y=-1 有 8 条
-
- :数据集中特征为 且为 类的数据数
- 通过统计数据集得到
- 计算条件概率
-
- 假设独立性
- 假设各特征之间相互独立,得到
- 假设独立性
-
- 算出所有分类的条件概率后,概率最大的分类即为分类结果
- 先计算各特征分类的概率
- 贝叶斯估计
- 极大似然估计可能会因为数据集中缺失,导致概率为 0
- 相比极大似然估计,在分子和分母上增加一项避免概率为 0
-
- :数据集中的统计量
- :类别个数
-
- :特征可取值
- :默认取 1
-
- 算出所有分类的条件概率后,概率最大的分类即为分类结果
- 极大似然估计
决策树
- 树形结构
- 结点
- 内部结点
- 特征/属性
- 叶结点
- 类
- 内部结点
- 有向边
- 结点
- 从根结点开始,递归选择最优的特征,直至实例分到叶结点的类中
- 常用算法
- ID3
- C4.5
- CART
- ID3 算法
- 结合信息增益,选择信息增益最大的作为结点,并建立子结点
- 经验熵
- 经验条件熵
- 信息增益
- 计算下个结点的信息增益时,要去掉父结点其他子结点的数据
- 若当前为 no,则要去掉 yes 分支的数据
第十章 社交网络
- 在线社交网络的核心要素
- 网络群体
- 关系结构
- 信息内容
- 信息内容特点
- 多样性
- 信息内容的话题不受限制
- 用户可以讨论任何话题
- 时时刻刻也会产生新的话题
- 平等性
- 用户可以平等的发布和传播信息内容
- 迅捷性
- 信息的发布和接受都非常方便
- 信息传播的距离极大缩短
- 蔓延性
- 信息内容的传播呈核裂变式,几何级数的增长
- 多样性
个体影响力计算
度中心性
- 网络内节点与邻居节点连边的数量
- 节点的邻居节点越多,该节点的影响力越大
介数中心性
- 一个节点成为其他任意两个节点最短路径上的必经之路的次数越多,重要性越大
-
- :节点 p 到节点 q 最短路径的数目
- :节点 p 到节点 q 最短路径中经过节点 i 的路径的数目
- 计算复杂度过高,无法快速计算
接近中心性
- 考察节点到任意节点最短路径的平均长度
-
- :节点 i 和节点 j 之间的最短距离
- 需要计算所有节点之间的最短路径长度,计算复杂度高
LH-index 算法
- 邻居节点的影响水平越高,该节点的影响力越高
- h 指数
- 衡量学者学术影响力
- h 篇被引用的论文,每篇都被引用至少 h 次
-
- :邻居节点的集合
- 和 :节点的比重,按需进行调整
PageRank 算法
- 与 [[0x03_Note/0x00_Content Security/信息内容安全#|信息检索部分的PageRank]] 是相同的
- TwitterRank 算法
- 矩阵 DT
-
- :第 i 个用户在第 j 个话题中的发帖数量
- 归一化处理
- 行归一化
- 记为 ,i 用户参与话题的概率
- eg
- 列归一化
- 记为 ,j 话题中用户参与的概率
- eg
- 行归一化
-
- 相似度
-
- 如果用户 i 关注用户 j,两者在 t 话题下的相似度
-
- 转移概率
-
- :用户 j 在话题 t 下发布的所有博文数量
- :用户 i 在所有好友的话题 t 下发布的所有博文数量
- 转移矩阵
-
- 用户 i 不一定关注用户 j 的情况
- 用户 i 的影响力矩阵
-
- : 的第 t 列
-
- 影响力
- :关注情况
- :未关注情况
- 用户 i 的影响力矩阵
- 矩阵 DT
信息传播模型
独立级联模型 ICM
- ICM 计算出的是概率值
- 有向图
- :用户
- 激活状态
- 未激活状态
-
- e :u-v 之间的边
- :用户
- 激活概率
- u 激活 v
- u 未激活 v
- 激活概率
- 随机取值
- 较小的固定取值
- 0.1
- 0.01
- 0.001
- …
- 入户线数倒数取值
-
- :(有向边)入户线数目
-
- 固定随机取值
- 随机取值
- u 激活 v
- 激活过程
- t=0 时刻,仅有种子集合
- 种子集合 S:初始激活的用户
- 当用户 u 在 t 时刻被激活,用户 u 仅可在 t+1 时刻激活其他用户
- 通俗解释
- 用户获得信息后,会在第一时间进行转发,而不是等一段时间后再转发
- 所以在模型中仅能在 t+1 时刻激活其他用户是符合传播过程的
- 通俗解释
- 激活状态
-
- 在 t 时刻被首次激活
-
- 未被激活
- 在 t 时刻前已被激活
- 激活应该是不可逆的
- 接收到信息后,就会被激活
-
- 激活概率
-
- t 时刻,v 被激活,需要 u 在 t-1 时刻被激活
- u 属于 v 的父结点集合
-
- t=0 时刻,仅有种子集合
线性阈值模型 LTM
- LTM 计算出的是确定值
- 父节点 u 对子节点 v 的影响力权重,且和小于等于 1
- 激活条件
- v 的所有父节点的影响力权重累积超过阈值 ,
- 越大,节点 v 越难被影响,即越难被激活
- 激活过程
- t=0 时刻,仅有种子集合
- 逐时刻进行判断是否满足上激活条件
- 若没有新的被激活节点出现,则传播过程结束
- 当网络结构、、 和 不变,那么整个传播过程都将是确定、不会改变的
传染病模型
- 模拟节点感染和恢复
- 常见模型
- SI
- SIR
- SIRS
- SEIR
- 节点分类
- S 类 - 易感者
- 未被激活,易被激活
- E 类 - 暴露者
- 被激活,但无法激活其他节点
- I 类 - 感染者
- 被激活,可以激活其他 S 类节点为 E 类或 I 类节点
- R 类 - 康复者
- 重新变为 S 类节点
- S 类 - 易感者