-
去标识 De-identification / 匿名 Anonymizaiton / 假名 Pseudonymization
从数据集中删除标识信息.
-
标识信息 / 个人标识信息 (Personally Identifiable Information, PII)
可以用于唯一标识的信息.
姓名, 地址, 电话号码, 电子邮箱, … -
如何去除 PII ?
删除即可.
会将一部分 PII 保留下来作为 辅助数据 (Auxiliary Data).
这些保留的标识信息可以被用于 重标识 (Re-identification) 攻击.
2.1 关联攻击 Linkage Attack
通过链接非匿名数据库来识别匿名数据库中的数据. 将可以标识个人的属性, 与其他信息数据库中的属性进行重合匹配. 从而匹配获得对应的信息. 例如, 出生日期+邮编+性别 可以大致 (通过年龄+地区+性别) 区别一个人.
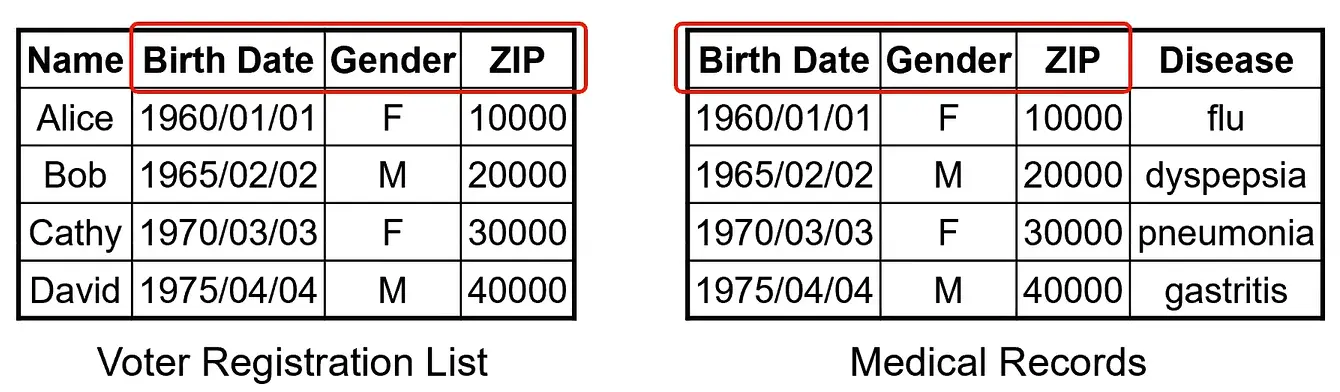
所以通过对比两个库中具有标识性的属性, 就可以将信息与人进行匹配, 进而获得信息.
- 重标识的难度很低
通过一个辅助数据就可以筛掉很多人, 用邮编就可以确定到一个地区, 再使用生日就能更大的缩小范围. 在书中示例数据集中, 邮编和生日的数据出现次数都很少, 几乎每个邮编和生日都仅出现 1 次, 使用邮编和生日进行重标识攻击, 可以重标识出所有的个体.
2.2 聚合 Aggregate
防止隐私信息泄露的一种方法.
通过计算平均值来避免单一个体的信息泄露.
adult['Age'].mean()
2.2.1 小群组问题
聚合处理 可以提升隐私保护效果. 多数情况需要对数据进行分组, 再进行聚合处理. 但是对于个体数量少的分组, 计算出的平均值也就相当于直接泄露了.
小分组的个体信息隐藏问题 是一个普遍存在的问题. 并且即使分组够大, 聚合处理也不能完全达到隐私保护的目的.
2.2.2 差分攻击
通过多次查询获得值, 来计算平均值获得更准确的真实平均值. 随机数有正有负, 长期来看会相互抵消, 所以这个平均值会越来越接近真实的平均值.
import numpy as np
# 差分隐私机制(查询返回值添加随机噪声)
def differentially_private_mean(data, epsilon):
true_mean = np.mean(data)
noise = np.random.laplace(0, 1.0 / epsilon)
return true_mean + noise
# 数据集
dataset = np.array([30, 40, 50, 60, 70])
# 差分隐私查询
epsilon = 0.1
private_result = differentially_private_mean(dataset, epsilon)
print(f"差分隐私查询结果: {private_result}")
# 模拟差分攻击
num_queries = 10000
query_results = [differentially_private_mean(dataset, epsilon) for _ in range(num_queries)]
estimated_mean = np.mean(query_results)
print(f"真实平均值: {np.mean(dataset)}")
print(f"通过差分攻击估计的平均值: {estimated_mean}")
通过查询所有记录总和和查询除目标外的所有记录综合, 两者的差值即为目标的隐私数据.
import pandas as pd
# 数据集
data = {
'Name': ['John', 'Jane', 'Alice', 'Doe', 'Bob'],
'Salary': [50000, 60000, 55000, 50000, 70000]
}
people = pd.DataFrame(data)
# 输出人员
print(people)
print("Total Salary:", people['Salary'].sum())
print("Total Salary without John's:", people[people['Name'] != 'John']['Salary'].sum())
print("John's Salary: ", people['Salary'].sum(), "-", people[people['Name'] != 'John']['Salary'].sum(), "=", people['Salary'].sum()-people[people['Name'] != 'John']['Salary'].sum())
存在问题:
- 发布可用性很高的数据会提高隐私保护的难度.
??? 可用性很高 => 越准确越真实的数据
- 很难区分恶意和非恶意问询.